CTFS Tutorials
Source file: http://ctfs.si.edu/ctfsdev/CTFSRPackageNew/files/tutorials/GrowthChangeGrowth changes
GROWTH VARIATION THROUGH TIME
Date: July 7, 2012.
The question addressed here is how growth has changed with time, in particular how species differ in growth changes. There are two alternative models described:
- Growth rate changing linearly with time
- Growth rate varying from census to census, but not following a consistent change
Both hypotheses will be tested running models with the R function lmer in the package lme4. You will need to install the package.
1. Formatting data
The calculations start with the full plot dataframes described at http://ctfs.arnarb.harvard.edu/Public/CTFSRPackage/help/RoutputFull.pdf. The BCI data can be downloaded from http://ctfs.arnarb.harvard.edu/bci/RAnalyticalTables after filling out the request form http://ctfs.arnarb.harvard.edu/webatlas/datasets/bci/.
In the CTFSRPackage, there are functions for loading data and calculating growth rates. The function individual_grow.table collects results from several other functions to calculate growth rates for individual trees and assemble them into a table in the format used by lmer. It is described in the Demography package.
The purpose is to create tables of growth rates for every tree in every census interval. Choose any diameter category, and any set of censuses you wish to work with. Here is an example for big trees at BCI (dbh ≥ 400), with all seven censuses included.
39 000022 989.1 421.3 anacex 1761 1855 1.12953376 22.843313 3.128658 4.087348 -8.305270 1 1
59 000044 991.8 342.5 loncla 655 670 0.14053188 3.662266 1.298082 1.793442 -8.328542 1 1
102 000087 985.6 226.5 anacex 426 533 -0.28966401 26.229362 3.266879 4.349652 -8.344969 1 1
103 000088 983.7 229.4 tri2tu 553 587 -0.02874535 8.334564 2.120411 2.596554 -8.344969 1 1
104 000089 988.9 232.8 alsebl 642 661 0.12048495 4.657550 1.538490 1.998347 -8.344969 1 1
117 000102 994.2 185.3 huracr 732 837 0.25167716 25.825758 3.251372 4.319405 -8.354552 1 1
The table grate has one row per individual growth measurement, and includes the tree’s tag number, coordinates, species, and dbh at two time periods. The column census gives the census interval, so 1 means growth between census 1 and 2, and 2 means growth from census 2 to 3, etc. The column censusfact is the same, but as a factor variable instead of an integer. The time column is the mid-point of the interval over which growth was measured, centered on 1992. This is the format needed by lmer. The reason for centering time is that it is much better in linear regressions to have the x-axis near zero.
The argument rnd indicates that dbhs<50 mm are rounded down to 5-mm, necessary because saplings at BCI in 1982 and 1985 were measuring in 5-mm increments. The growth functions in the CTFS R Package handle this.
The other columns are
- LnSize: log(dbh1)
- incgr: growth increment (difference in dbh) per year
- LnGrowth: log of the growth rate, with negatives and zeroes converted to 0.1 (from the argument mingrowth in the function)
- CRGrowth: power transformation of the growth rate, with negatives maintained negative (exponent = 0.45).
The analyses are most cleanly done using the cube root of growth rate (CRGrowth), so no assumptions about negative growths are needed. You are welcome to try either untransformed growth increment (incgr) or the log of growth (LnGrowth).
2. Mean forest-wide growth
First find the mean growth rate of all individuals in each census period using the table grate.
Calculate mean growth increment per census interval, and the mean(incgr) and mean(CRGrowth). These are simply the observed mean growth rates in all 6 census intervals. The time, meanyr, is the mean years since 1992 of each census interval.
> increment=tapply(grate$incgr,grate$census,mean)
> increment.med=tapply(grate$incgr,grate$census,median)
> root=tapply(grate$CRGrowth,grate$census,mean)
> root.med=tapply(grate$CRGrowth,grate$census,median)
> meanGrowth=data.frame(meanyr,increment,increment.med,root,root.med)
> meanGrowth
1 -8.341837 10.280166 8.380528 2.456828 2.602987
2 -3.963116 7.510867 5.092428 1.991760 2.080253
3 1.207770 4.644751 3.349970 1.604515 1.722932
4 6.046461 5.183409 3.422960 1.731147 1.739726
5 11.042803 4.777542 3.326767 1.650958 1.717547
6 16.079248 5.080532 3.644401 1.744470 1.789500
Graph mean growth vs. time. In this example, I use the mean of the cube-root of growth, but cube it to return to the original scale. You could also simply graph the mean growth increment.
> par(cex=1.5)
> plot(I(root^(1/expon))~meanyr,data=meanGrowth,type='l',xlab='years since 1992',ylab='median growth increment',xlim=c(-10,17),ylim=c(0,9))
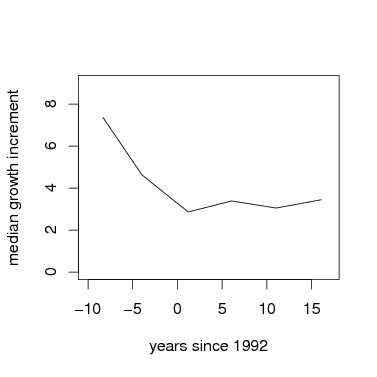
3. Mixed model to assess species variation in linear changes through time
The function lmer runs a linear regression of growth rate vs. time, with species as a random effect. This is equivalent to a hierarchical model, where a Gaussian distribution describes the variation in species responses. The cube root of growth is used as the response, in order to come closer to a normal error term (required in textitlmer) while not requiring artificial exclusion of negative growth rates (as a log-tranformation would).
Since BCI growth rates declined over the first 3 censuses, but have not changed since, I chose to run separate models for census ≤ 3 and census ≥ 3. You may want to make a similar division, or run a single model with all censuses at once.
> gmod2=lmer(CRGrowth~1+time+(1+time|species),data=subset(grate,census>=3),verbose=TRUE)
The 1 + time component means to fit a model of CRGrowth against time, with an intercept (the 1). The next component, (1 + time|species) means that the intercept and slope should both be allowed to vary across species. Then (1+time|tag) accounts for repeated measures of individuals by using the tree tag (identifying individual trees) as a random effect.
The coefficients of each model are the key result. The fixed effect gives the forest-wide response, which is the average growth of the species. It is thus not the same as the mean forest-wide growth, because the fixed effect weights each species equally.
The following graph uses the function fixef to get the parameters, then the function curve to add them to the graph. The points are forest-wide means, as graphed above.
> plot(root~meanyr,data=meanGrowth,pch=16,xlab='years since 1992',ylab='median growth',ylim=c(1,3),xlim=c(-10,17),axes=FALSE,cex=2)
> box()
> axis(1)
> axis(2,at=pospower(c(.2,1,3,5,8,10,15,20),expon),label=c(.2,1,3,5,8,10,15,20))
> par=fixef(gmod1); curve(par[1]+x*par[2],from=(-10),to=0,add=TRUE)
> par=fixef(gmod2); curve(par[1]+x*par[2],from=0,to=17,add=TRUE)
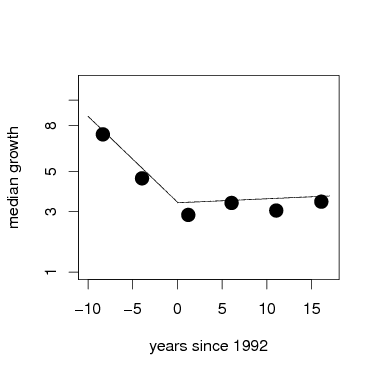
3.2. Repeated measures of individuals.
With lmer, accounting for the repeated measures of individual trees is easy to model. The tree tag, which identifies individuals, is added as a random effect. This is a fully nested model, individual within species. Here are the same two models as above, but now with tag added as a random effect. The graph overlays fixed effects from both models, with the model including tag in green.
> gmod2tag=lmer(CRGrowth~1+time+(1+time|species)+(1+time|tag),data=subset(grate,census>=3),verbose=TRUE)
> plot(root~meanyr,data=meanGrowth,pch=16,xlab='years since 1992',ylab='median growth',ylim=c(1,3),xlim=c(-10,17),axes=FALSE,cex=2)
> box()
> axis(1)
> axis(2,at=pospower(c(.2,1,3,5,8,10,15,20),expon),label=c(.2,1,3,5,8,10,15,20))
> par=fixef(gmod1); curve(par[1]+x*par[2],from=(-10),to=0,add=TRUE)
> par=fixef(gmod2); curve(par[1]+x*par[2],from=0,to=17,add=TRUE)
> par=fixef(gmod1tag); curve(par[1]+x*par[2],from=(-10),to=0,add=TRUE,col='green')
> par=fixef(gmod2tag); curve(par[1]+x*par[2],from=0,to=17,add=TRUE,col='green')
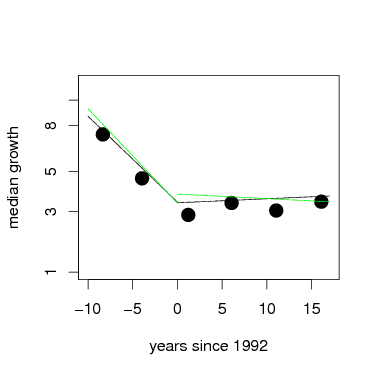
3.3. Statistical signficance of the fixed effects.
Use the function display from the arm package to summarize the model results. All four models are displayed below.
The first section printed to the screen by display is the fixed effect, including both the coefficients (first column) and their standard error (second column). The term for time is how growth changed through time, negative numbers showing it declined. Confidence limits can be estimated by adding and subtracting 2 times the standard error. Display also repeats the model, to help keep track of which is which.
Whether or not tag was added to the model, the fixed effect of time shows that the average response was negative, and highly significantly so, over the first 3 census intervals. The models for census 3 and beyond, though, inclusion of tag alters the fixed effect: growth rate increased significantly when tag is not in the model, but adding tag changes the effect to slightly negative, though not significant. The graph above shows this; note that the differences are slight.
3.3.1. Model for census intervals 1-3, without tag.
census <= 3), verbose = TRUE)
coef.est coef.se
(Intercept) 1.74035 0.07332
time -0.09083 0.00841
Error terms:
Groups Name Std.Dev. Corr
species (Intercept) 0.59095
time 0.04298 -0.30013
Residual 1.25747
---
number of obs: 3775, groups: species, 108
AIC = 12662.8, DIC = 12628.6
deviance = 12639.7
3.3.2. Model for census intervals 1-3, with tag.
time | tag), data = subset(grate, census <= 3), verbose = TRUE)
coef.est coef.se
(Intercept) 1.73024 0.07287
time -0.09990 0.00828
Error terms:
Groups Name Std.Dev. Corr
tag (Intercept) 0.46947
time 0.04907 -1.00000
species (Intercept) 0.58338
time 0.04262 -0.19470
Residual 1.09077
---
number of obs: 3775, groups: tag, 2195; species, 108
AIC = 12555.7, DIC = 12515.4
deviance = 12526.5
3.3.3. Model for census intervals 3-6, without tag.
census >= 3), verbose = TRUE)
coef.est coef.se
(Intercept) 1.73344 0.07290
time 0.00424 0.00253
Error terms:
Groups Name Std.Dev. Corr
species (Intercept) 0.64072
time 0.00535 -0.51690
Residual 1.03625
---
number of obs: 6411, groups: species, 112
AIC = 18910.3, DIC = 18870.9
deviance = 18884.6
3.3.4. Model for census intervals 3-6, with tag.
time | tag), data = subset(grate, census >= 3), verbose = TRUE)
coef.est coef.se
(Intercept) 1.82540 0.07471
time -0.00481 0.00271
Error terms:
Groups Name Std.Dev. Corr
tag (Intercept) 0.72387
time 0.02603 -0.53405
species (Intercept) 0.62677
time 0.01046 -0.47723
Residual 0.82199
---
number of obs: 6411, groups: tag, 2514; species, 112
AIC = 18295.7, DIC = 18250.6
deviance = 18264.2
3.4. Individual species variation.
The real strength of lmer comes from the examination of how individual species vary. In the output of display, there are summary coefficients called Error terms. Each of these is a standard deviation across species: it measures how different species are.
Consider first the intercept in the first model, with tag included (the model named gmod1tag). The fixed effect, or average intercept of all species, is 1.38. But species differ, with standard deviation 0.39. Recall that most results fall within 2 standard deviations of the mean. This means that individual species have intercepts as high as 2.16 (1.38 + 2 × 0.39), and others as low as 0.60. Recall also that those are cube roots, since the model was run with CRGrowth.
But the main point has been how growth rate varies through time, given as the time parameters. Under Error terms, the species effect for time is 0.026, and the fixed effect −0.0599. This means that the nearly the entire distribution of species responses falls < 0, meaning nearly all species had declining growth. In the second time interval (after census 3), species level variation was lower by a factor of 4.
There are additional Error terms for the tag, and a Residual term. The former shows variation among individuals within a species; notice it is approximately as high as the species term. The latter, Residual, is all remaining variation, which means variation in growth rates of individual trees in different census intervals, after accounting for the time effect. It is always higher than either species-level or individual-level variation, meaning most of the variance in growth is unexplained by the model.
3.5. Individual species responses.
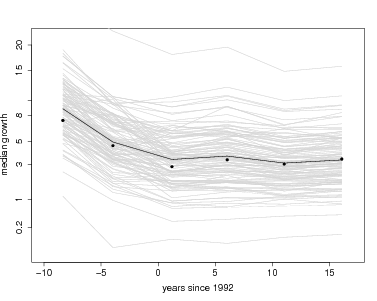
But lmer returns more: a set of coefficients for every species, and these make for direct interpretation. The function coef, also in the arm package, returns all coefficients. Here is graph overlaying every individual species onto the graph of fixed effects, using the models with tag included. The entire set of species coefficients are returned by coef(gmod1tag)$species; here I save those into a temporary variable called cf to reduce the amount of typing. There is a loop through every species, using the function curve to overlay one species’ results with a gray line. Since I chose to run models for two separate intervals of time, I repeat this for gmod1tag then gmod2tag. At the end, I add the fixed effects again, just as above, plus points for the forest-wide means.
Visually it is evident first that most of the variation between species is in the intercept term, while slopes of the lines are fairly consistent.
> plot(root~meanyr,data=meanGrowth,pch=16,xlab='years since 1992',ylab='median growth',ylim=c(0,4),xlim=c(-10,17),axes=FALSE)
> box()
> axis(1)
> axis(2,at=pospower(c(.2,1,3,5,8,10,15,20),expon),label=c(.2,1,3,5,8,10,15,20))
> cf=coef(gmod1tag)$species
> nospp=dim(cf)[1]
> for(j in 1:nospp) { par=drp(cf[j,]); curve(par[1]+x*par[2],from=(-10),to=0,add=TRUE,col='lightgray') }
> par=fixef(gmod1tag); curve(par[1]+x*par[2],from=(-10),to=0,add=TRUE)
> cf=coef(gmod2tag)$species
> nospp=dim(cf)[1]
> for(j in 1:nospp) { par=drp(cf[j,]); curve(par[1]+x*par[2],from=0,to=17,add=TRUE,col='lightgray') }
> par=fixef(gmod2tag); curve(par[1]+x*par[2],from=0,to=17,add=TRUE)
> points(root~meanyr,data=meanGrowth,pch=16)
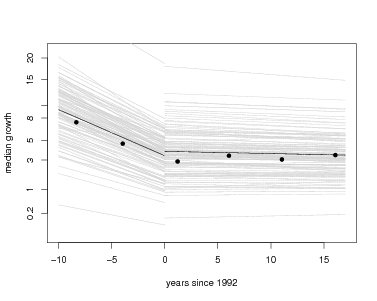
Coefficients can also be evaluated for individual species. Here are a few examples:
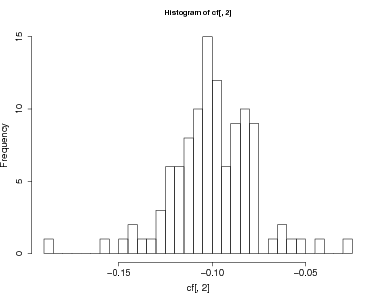
- Make a histogram of all growth responses to time
- Find the species with the biggest decrease in growth in the first interval
- Find the species with the highest growth intercept (growth in the very first census interval)
Other ideas to consider:
- Do species with higher initial growth show bigger changes in growth?
- Are species with lower growth rates more stable (less change through time)?
- Do saplings respond similarly to big trees (ie, repeat the model for dbh range 10-50 mm, or other sizes)?
alchco 1.399341 -0.12582794
alsebl 1.161360 -0.12312937
anacex 1.775811 -0.11828654
apeime 1.579989 -0.10256153
aspicr 2.430338 -0.12140099
ast2gr 1.744435 -0.09841568
> hist(cf[,2],breaks=25)
> mineffect=min(cf$time)
> subset(cf,time<(mineffect+.03))
4. Mixed model to assess species variation and temporal variation
An alternative model of growth change is to consider each census interval as a separate effect on growth, but without a linear change of growth through time. This would be reasonable if there is no a priori reason to expect steady increase (or decrease) in growth rate with time. Growth is allowed to vary from one census interval to the next, but can increase then decrease, etc.
The same function, lmer can be used, but now time is not a numeric variable, but simply a factor. The table already created, grate, has a column called censusfact, simply a number designating census intervals, but a factor, not an integer. Check this using R’s function str.
$ tag : Factor w/ 394658 levels "000001","000002",..: 22 42 85 86 87 100 109 112 114 117 ...
$ gx : num 989 992 986 984 989 ...
$ gy : num 421 342 226 229 233 ...
$ species :Class 'AsIs' chr [1:8594] "anacex" "loncla" "anacex" "tri2tu" ...
$ dbh1 : num 1761 655 426 553 642 ...
$ dbh2 : num 1855 670 533 587 661 ...
$ LnSize : num 1.1295 0.1405 -0.2897 -0.0287 0.1205 ...
$ incgr : num 22.84 3.66 26.23 8.33 4.66 ...
$ LnGrowth : num 3.13 1.3 3.27 2.12 1.54 ...
$ CRGrowth : num 4.09 1.79 4.35 2.6 2 ...
$ time : num -8.31 -8.33 -8.34 -8.34 -8.34 ...
$ census : int 1 1 1 1 1 1 1 1 1 1 ...
$ censusfact: Factor w/ 6 levels "1","2","3","4",..: 1 1 1 1 1 1 1 1 1 1 ...
species) + (1 + censusfact | tag), data = grate, verbose = TRUE)
coef.est coef.se
(Intercept) 2.67142 0.07935
censusfact2 -0.61261 0.08015
censusfact3 -0.93478 0.05123
censusfact4 -0.87213 0.05628
censusfact5 -1.00056 0.06078
censusfact6 -0.94397 0.05897
Error terms:
Groups Name Std.Dev. Corr
tag (Intercept) 1.26659
censusfact2 1.35732 -0.54839
censusfact3 1.43672 -0.74911 0.53463
censusfact4 1.46371 -0.78743 0.49107 0.75629
censusfact5 1.40874 -0.76929 0.49858 0.77132 0.81182
censusfact6 1.42524 -0.81308 0.47697 0.75210 0.81110 0.84821
species (Intercept) 0.61296
censusfact2 0.43278 -0.13771
censusfact3 0.10586 -0.07647 -0.97704
censusfact4 0.18226 0.03177 -0.09761 0.09142
censusfact5 0.24610 -0.35441 -0.33870 0.41719 0.52324
censusfact6 0.22489 -0.32887 -0.20292 0.27501 0.90874 0.75923
Residual 0.51463
---
number of obs: 8594, groups: tag, 2915; species, 117
AIC = 25801.4, DIC = 25652.1
deviance = 25677.7
alchco 2.199290 1.893568 1.206482 1.231768 1.090932 1.176831
alsebl 2.034442 1.804900 1.028999 1.135727 1.186920 1.142104
anacex 2.852773 1.749827 2.031993 2.109793 1.854495 2.042376
apeime 2.481010 2.004804 1.519715 1.574147 1.360332 1.494409
aspicr 3.524504 2.862907 2.570096 2.715779 2.381153 2.526847
ast2gr 2.668086 2.144479 1.711514 1.866825 1.691429 1.794633
beilpe 2.489426 2.130865 1.498851 1.639936 1.500277 1.576951
brosal 2.731282 2.850323 1.614121 1.910540 1.629591 1.776187
calolo 3.178381 2.577939 2.221772 2.326024 2.075281 2.179417
casear 2.419540 1.697821 1.520982 1.497000 1.390089 1.453227
cassel 2.558397 1.956781 1.625108 1.685204 1.573924 1.628065
cavapl 3.237805 2.683662 2.267588 2.718407 2.367018 2.602800
The coefficients are returned in the same way as they would be by R’s function lm. The intercept term is the estimated growth rate (cube root) in whatever census period comes first (in this case, censusfact=1). The remaining coefficients show the difference between growth in each of the other censuses and the first one. Thus, the intercept has to be added to the remaining coefficients in order to get the growth rate. The line with cf[,2:6] makes that adjustment, so that the temporary variable cf has the mean growth rates (root transformed) in each census period.
In the graph in which the x-axis is time, the responses will not be straight lines because the assumption of linear change has been removed.
Coefficients of every species can be evaluated to examine hypotheses about how growth differed between census intervals. For example, at BCI, the fixed effect of this model shows that the highest average growth was in the 1st interval, and species were extremely consistent about this: 115 of 117 had their highest growth rates in the first interval. The lowest average growth was the 5th interval, but the difference among intervals 3-6 was small, and species were much less consistent: 77 had their lowest growth rate in the 5th interval, but 11 did so in the 2nd and 16 others in the 3rd. Ten species’ lowest growth was in the final interval.
- How many species had their highest growth in the first census interval?
- How many species had their lowest growth in the last interval?
- Did growth rate in the first interval correlate with growth in the last?
- Do saplings respond similarly to big trees (ie, repeat the model for dbh range 10-50 mm, or other sizes)?
> plot(root~meanyr,data=meanGrowth,pch=16,xlab='years since 1992',ylab='median growth',ylim=c(0,4),xlim=c(-10,17),axes=FALSE)
> box()
> axis(1)
> axis(2,at=pospower(c(.2,1,3,5,8,10,15,20),expon),label=c(.2,1,3,5,8,10,15,20))
> fx=fixef(gmodTimefact)
> cf=coef(gmodTimefact)$species
> cf[,2:6]=cf[,2:6]+cf[,1]
> fx[2:6]=fx[2:6]+fx[1]
> nospp=dim(cf)[1]
> for(j in 1:nospp) lines(meanyr,cf[j,],col='lightgray')
> lines(meanyr,fx)
> points(root~meanyr,data=meanGrowth,pch=16)
5. File Creation
> system("pdflatex DemogChangeGrowth");
> system("htlatex DemogChangeGrowth");system("mv DemogChangeGrowth* ~/ctfs.comparisons/demography/GrowthChange/");
> system("cp -r ~/ctfs.comparisons/demography/GrowthChange /var/www/Public/CTFSRPackage/files/tutorials/"); system("mv /var/www/Public/CTFSRPackage/files/tutorials/GrowthChange/DemogChangeGrowth.html /var/www/Public/CTFSRPackage/files/tutorials/GrowthChange/index.html")
> system("rm DemogChangeGrowth/*")